![]()
![]()
![]()
![]()





|
|
|
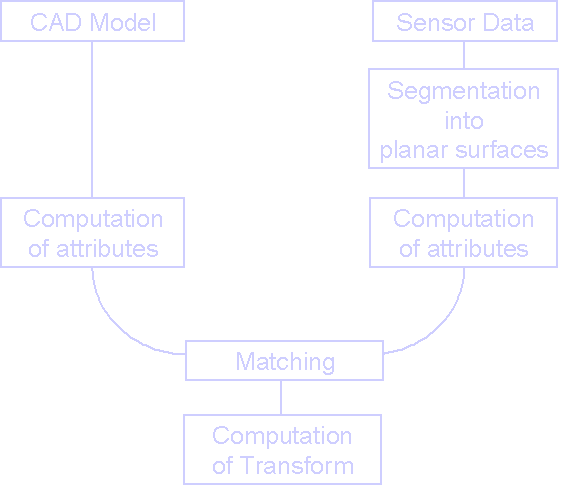
| Object RecognitionObject recognition can be used to identify an unknown object and to determine it's pose with respect to a certain coordinate system. In general, object recognition is the task of assigning one set of features, the scene features, a set of corresponding features in the model. If the number of scene features is denoted with n and the number of model features is denoted with n, there are in principle O(nm) possible pairings. In our context, the features might be equivalent to surfaces. Of course only a small number of the possible pairings are valid correspondences. To cope with the computational burden imposed by the given problem, we have to find a representation that on the one hand is efficient to evaluate and on the other hand allows to exclude large areas of the search space.
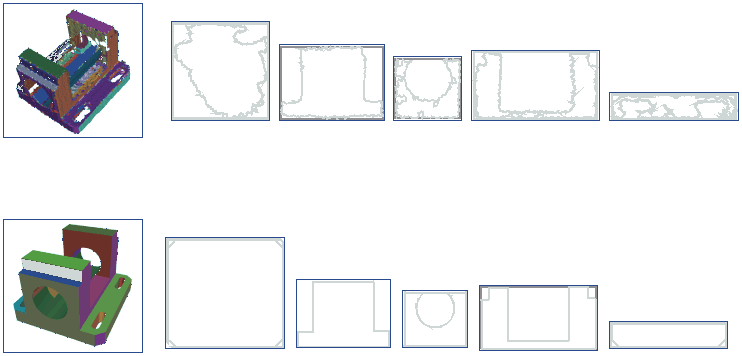
We use the method of Constrained Tree Search. Based on a segmentation of the object into planar surfaces we compute a number of characteristic figures for each planar patch. Unary constraints discriminate invalid matches. More significant features are evaluated first. Binary constraints allow to prune complete branches of the search tree.
Once a consistent solution is found, we compute the rigid body transformation that aligns the to objects (using the region centers as corresponding points). If the residuals of this solution is within a given tolerance, we compute as a last test the deviation between the two surfaces.
If the two objects pass all tests, we can go on to registration and validation steps. As future work we want to integrate learning methods known from Artificial Intelligence that allow the system to benefit from knowledge gained from previous tasks.
|
|
|